

Wan-S2Vの必要VRAMとGPU要件のリアル
Wan-S2V(Wan2.2-S2V-14B)は、音声からリアルな動画を生成する先進的なAIモデルです。しかし、その高い生成品質を実現するためには、非常に大きなGPUメモリ(VRAM)を必要とします。Hugging Faceで公開されている同モデルの動作条件では、最低でも80GBのVRAMを搭載したGPUが推奨されています。例えば、NVIDIA A100(80GB)やH100といったハイエンドGPUが必要です。一般的なクリエイターや個人ユーザーが所有するRTX 4090(24GB)ではフルモデルを扱うことは難しいのが現状です。
このVRAM要件の背景には、Mixture-of-Experts(MoE)と呼ばれる専門家モデルを複数組み合わせた構造があり、計27Bパラメータを持ちながらも、1ステップの実行には14B相当の活性化のみで済むという工夫がされています。動画生成AIは画像生成AIに比べて時系列処理が必要であり、フレーム間の整合性を保つために膨大なメモリを消費します。さらに、–offload_model True や –convert_model_dtype オプションによって、ある程度のメモリ節約も可能ですが、実質的には80GBクラスがほぼ必須となります。
一方、TI2V-5Bという軽量モデルが用意されています。こちらは「Text-Image-to-Video(テキストや画像を入力に動画を生成するモデル)」で、Wan-S2Vとは用途が異なります。Wan-S2Vが音声駆動で人物動画やリップシンク生成に強みを持つのに対し、TI2V-5Bはテキストや画像からシーン全体の映像を作るのに適しています。公式実装では単一GPU・24GB VRAM(例:RTX 4090)で720p/24fpsの推論に対応しますが、ComfyUIのオフロードを利用すれば8GB VRAMでも動作報告があり(速度や安定性に制約あり)、初心者の試行にも現実的な選択肢となります。本記事ではVRAM要件の目安として参考比較に挙げています。関連記事:Wan2.2の全貌を徹底解説
単一GPU vs マルチGPU:どちらで運用すべきか
単一GPU運用では、FP8スケールや型変換の工夫で80GB VRAMがあれば一応の実行が可能です。しかし、バッチサイズや出力解像度の自由度を高めるには、マルチGPUによる分散処理(DeepSpeedやFSDPの導入)が効果的です。特に研究者やプロの映像制作では、4枚以上のGPUを並列化して大規模な生成を行うケースもあります。今後クラウドGPU環境を前提とした運用も増えると見られ、個人ユーザーはレンタルGPUサービスを利用するのも現実的な選択肢です。
TI2V-5Bの“24 GB運用”が実現する手軽さ

TI2V-5BはWanシリーズの別系統で、テキストや画像を入力に動画を生成するモデルです。用途はS2Vと異なりますが、VRAM要件が軽いため比較の参考として紹介します。公式実装では24GB VRAMで720p対応が可能であり、オフロードを活用すれば8GB環境でも動作報告があります(ただし速度や安定性に制約あり)。この軽量性により、特に「まずはAI動画生成を試してみたい」という個人クリエイターに適した選択肢です。
初心者と中級者でのGPU選択の違い
初心者は自分の手元の環境に近い小規模モデルから試すのが適切です。例えばRTX 3060や3090でも動作報告がある軽量版を選び、最初は低解像度で出力することがポイントです。一方で中級者以上は、レンタルGPUやクラウドを活用し、TI2V-5Bではなくフルモデルに挑戦することでより高品質な動画生成にチャレンジできます。
主要動画生成AIの比較
| モデル | 必要VRAM | 特徴 | 対象ユーザー |
|---|---|---|---|
| Wan-S2V 14B | 80GB以上 | 音声主導で高品質動画を生成、映画的表現に強い | 研究者、映像制作プロ |
| TI2V-5B | 24GB(8GBでもオフロードで可) | テキストや画像から動画生成、軽量かつ720p対応 | 初心者~中級クリエイター |
| Google Veo 3 | クラウド依存 | 高解像度動画生成、映像業界向け | 法人・スタジオ |
| Runway Gen-3 | クラウド依存 | テキスト主導型でSNS向け動画制作に強い | 初心者~中級者 |
Wan-S2Vの将来展望:映画品質映像への進化
Wan-S2Vは単なる音声同期のアニメーションではなく、映画品質の「動き」「表情」「カメラ演出」まで統合的に生成可能な次世代モデルです。これは映像制作の現場やコンテンツクリエイションにおいて、革命的なツールとなるポテンシャルを秘めています。既存のRunway Gen-3やGoogle Veo 3と比較しても、音声主導の自然な映像表現という点で優位性を持っています。
長尺動画でも安定:フレーム圧縮技術の実際
従来の動画生成AIは長尺になるほど品質が劣化しやすいという課題がありました。Wan-S2Vでは、フレームのトークンを階層的に圧縮し、最大73フレームまで過去情報を保持することで、滑らかな長尺映像を維持する工夫がなされています。これにより、1分以上の動画でも自然な動きが実現でき、ショート動画だけでなく本格的な作品制作にも利用可能となります。
ComfyUI対応:操作性の向上と普及拡大
ComfyUIにネイティブ対応していることで、プログラミング知識がなくてもGUIベースで直感的に操作できます。ワークフローの可視化、モジュールの差し替え、パラメータ調整が簡単で、初心者から中級者まで幅広く利用可能です。これにより、非エンジニア層への普及が一気に加速しています。
MoE構造の優位性:品質と効率の両立
Wan-S2VのMoE構造は、27Bものパラメータを持ちながら、必要な専門家ブロックのみを活性化させる仕組みによって、計算コストを抑えつつも非常に高い品質を維持します。このアーキテクチャは、今後他のAIモデルでも導入されると考えられ、効率的な大規模モデルの新たなスタンダードとなる可能性があります。
複数キャラクターと動的カメラ:映画的進化の次段階
現在は主に1人の人物に焦点を当てた動画生成が中心ですが、将来的には複数のキャラクターが会話や演技を行うシーン、動的に移動するカメラ、背景とのリアルな相互作用などが研究されています。これにより、短編映画やYouTube動画、さらには広告映像の自動生成が可能になるでしょう。関連:WanGPでMultitalkを使う方法
副業やSNSでの活用シナリオ
個人ユーザーにとっての魅力は、副業やSNS運用への応用です。例えばYouTubeショートやTikTok用のリップシンク動画、音楽に合わせたパフォーマンス動画、VTuber活動の補助など、多様な形で収益化につなげることができます。クラウドGPUサービスを利用すれば、PC環境が貧弱でも外注感覚で高品質動画を生成可能です。関連記事:InVideo AI徹底解説も参考になります。
クラウドGPUサービスの選び方
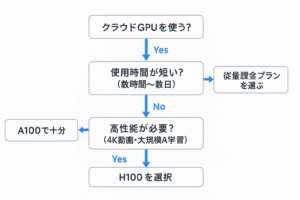
Wan-S2Vを扱うためにクラウドGPUを活用する場合、料金体系と対応GPUが重要です。Google Cloud、Lambda Labs、RunPodなどではA100やH100を時間単位で利用できます。長時間の生成を行うなら従量課金よりも月額プランを選ぶ方がコストパフォーマンスに優れます。また、FP8モデルを利用すればクラウドの時間単価を抑えることができ、初心者にとって負担が軽減されます。
注意点とよくある失敗
一方で、Wan-S2Vを扱う際には注意すべき点もあります。最も多いのはVRAM不足によるクラッシュ(動作停止)です。解決策としては、低解像度から試す、オフロード設定を有効化する、またはクラウドGPUを利用する方法が挙げられます。また、長尺動画では音声との同期がずれることがあり、これはプロンプトの工夫やカット割りの調整が必要です。初心者は短尺から始めて、徐々に長尺に挑戦するのが失敗を避けるコツです。
このように、Wan-S2Vは映像制作AIとしての機能性と将来性を兼ね備えた非常に注目すべき技術です。今後のアップデートや応用範囲の拡大に要注目であり、映像クリエイターや副業を目指す方にとって有力な選択肢となるでしょう。

未来への展望:低VRAM時代のSound-to-Videoは可能か?
- 現段階では、サウンドから動画生成(S2V)は高いVRAM(最低24GB以上)が必要です。
- ただし、テキストや画像から動画生成(T2V・I2Vなど)は、低VRAM環境でも実用化が進んでおり、6GB程度でも動画生成が可能な技術(FramePackなど)も登場しています。
- さらに、Wan-S2Vを含むWan2.2モデルは、FP8量子化やレイヤーごとの低VRAMオフロードなどの最適化機構が導入されており、今後「低VRAM環境でS2Vが使える可能性」が現実味を帯びてきています。
- また、Hugging FaceやGitHubで有志による積極的な研究・実装(Diffusers / ComfyUIへの導入など)も進んでおり、コミュニティからの貢献が今後の技術普及に期待を持たせています。
以上のポイントから、将来的にはより手頃なVRAM環境でも「サウンドから動画生成」が可能になるかもしれないという、筆者個人の期待も込めています。
まとめと次の一歩
本記事では、Wan-S2VのVRAM要件とGPU選択、将来展望について解説しました。現状では80GBクラスのGPUが必須ですが、軽量モデルやクラウドGPUを利用することで多くのユーザーがAI動画生成を試すことが可能です。さらにコミュニティ研究や技術革新により、将来的には低VRAM環境でもサウンドから動画を生成できる時代が来るかもしれません。
次の一歩として: まずはクラウドGPUや軽量モデルを使って小規模な動画生成を試し、操作感をつかむことをおすすめします。その上で自分の目的に合わせた環境を選択し、副業やSNS運用に活用してみましょう。

関連記事
- Wan2.2の全貌を徹底解説|MoE構造と高圧縮モデルで副業にも最適
- AI動画生成の未来を変えるframepackとframepack eichiの徹底比較と使い方マニュアル
- EasyWan22の使い方と副業活用法|初心者向け動画生成ガイド


