

はじめに
本記事では、AI動画生成の分野で注目されている「Multitalk」を、動画生成プラットフォーム「WanGP」で利用する方法について、初心者にもわかりやすく丁寧に解説します。特に、低VRAM環境でも動作可能な設定や、Vaceモデルとの組み合わせ方法などを中心に紹介します。
Multitalkとは何か
Multitalkは、複数の人物が同時に会話する音声入力に応じて、それぞれにリップシンクや表情を同期させる多人数会話動画生成フレームワークです。学術的には、マルチストリーム音声を扱い、L‑RoPE(Label Rotary Position Embedding)という新しい技術で音声と人物の結びつきを正確に行います。
Multitalkの主な特徴
- 複数人物の音声を個別に認識して別々に動かせる。
- L‑RoPEにより音声と人物のバインディング精度が高い。
- 音声駆動型の映像生成に特化し、会話コンテンツ制作に強い。

WanGPとは何か
WanGP(通称:Wan2GP)は、GPU性能が低い環境でも動画生成AIを使えるように設計されたフレームワークで、いわゆる「GPU Poor(VRAMが6〜8GBの環境)」でも動作できるのが強みです。特に2025年7月現在のバージョン6.6や7.xでは、MultitalkやVaceモデルとの併用がサポートされており、ネット環境でも安定して動作します。
WanGPのメリット
- VRAMが6〜8GBでもMultitalkを使って多人数動画を生成可能。
- モデルや依存関係を自動インストールするWebベースUI。
- Vaceなど最新生成モデルを簡単に組み合わせ可能。
準備と前提条件
まず、以下の環境と手順を整えてください。
- GPU:VRAM6〜12GB程度(RTX 3060/4060など)
- WanGP v6.6以降の環境(GitHubのdeepbeepmeep/Wan2GPをインストール)
- ComfyUIを使う場合:必要なカスタムノード(WanVideoWrapperなど)を導入してワークフローを整える。
- 音声ファイル(.wav等)や参照画像/動画の準備。

ステップ1:WanGPのインストールと初期設定

まず、GitHub リポジトリ deepbeepmeep/Wan2GP をクローンします。
git clone https://github.com/deepbeepmeep/Wan2GP.git
次に、必要な依存ファイルやモデルを自動でセットアップし、WebベースのUIを起動します。バージョン6.6や7.xでは、Multitalkに対応するモデルが自動選択されます。
ステップ2:Multitalk対応のための設定
WanGP UI上で「Multitalk対応」を有効にするためには、Vaceモデルの読み込みやAudio_cfg_scaleの調整が必要です。低VRAM環境では、Vaceモデルと合わせて動作させることで精度が向上します。
加えて、ノイズ抑制設定(denoise_strength)を0.5前後に下げて、音声同期精度と映像応答のバランスを調整するのが推奨されています。
ステップ3:音声とリファレンス画像の準備
複数の声を用意する場合は、音声ファイルごとに名前を付けて整理します。参照画像やリファレンス動画も、それぞれの人物に対応するように準備します。
推奨ワークフローでは、参照画像はi2v(例:ModelScope)モデル、動画参照はt2v(例:Stable Video Diffusion)モデルを使い分けることで、リップシンクや体表現の精度が向上します。
ステップ4:生成処理とパラメータ調整
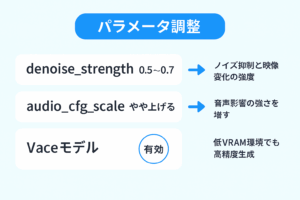
以下のようなパラメータ調整を行います。
| 項目 | 設定例 | 役割 |
|---|---|---|
| denoise_strength | 0.5〜0.7 | ノイズ抑制と映像変化の強度 |
| audio_cfg_scale | やや上げる | 音声影響の強さを増す |
| Vaceモデル | 有効 | 低VRAM環境でも高精度生成 |
生成を始めたら、小さなクリップから試して、上記パラメータを少しずつ調整しながら最適化していきます。
ステップ5:複数人物のバインディングと確認
Multitalkでは、複数の音声ストリームをそれぞれの人物に正しくバインドする必要があります。生成した動画を確認し、片方の声が別の人物の口で発せられていないか、表情や同期のズレがないかをチェックします。
よくあるトラブルと対処法
- Out of memory(メモリ不足) → フレーム数を減らす/低量子化モデル(fp8)を使う。
- 音声と人物が同期しない → denoise_strengthやaudio_cfg_scaleを調整。
- リファレンス画像が崩れる → 解像度を下げるかLoRAを挟む。
活用事例とSNS投稿の工夫
Multitalkで生成した動画は、X(旧Twitter)やInstagram、YouTube ShortsなどのSNSで高い注目を集めています。特にリップシンクが正確であるため、声優風キャラクター対話や仮想YouTuber(VTuber)の会話シーンに活用されています。短い会話スキットやストーリー風動画として投稿することで、ユーザーの関心を引きやすくなります。
他のAI音声合成ツールとの組み合わせ
Multitalkは、音声ファイルをトリガーとして映像を生成する仕組みのため、音声合成AIとの相性が抜群です。例えば、ElevenLabsやCoeiroInk、VOICEVOXなどのAI音声で台詞を作成し、その音声をMultitalkで使うことで、完全自動化された対話アニメーションを作成できます。これにより、YouTubeコンテンツや教育教材の制作も効率化できます。
専門用語の解説
L‑RoPE
Label Rotary Position Embeddingの略で、人物の音声ストリームを正確に結びつけるための位置エンコーディング手法です。これにより、異なる音声ソースを別々の人物に対応させる精度が向上します。
Vaceモデル
映像生成における高精度な顔表現モデルで、Multitalkと組み合わせることでリップシンクや表情の自然さが向上します。
denoise_strength
映像のノイズを除去する強度を表すパラメータで、値を下げるほど元の画像に忠実になりますが、音声との同期精度が下がる可能性もあります。
実際の生成例のステップバイステップ
以下は、Multitalkを使った実際の生成フローの例です:
- VOICEVOXで「こんにちは、今日のニュースをお伝えします」という音声を作成
- 女性キャラの参照画像を用意し、WanGPに読み込む
- 音声と画像をMultitalkモジュールでペアリング
- パラメータを設定(denoise_strength=0.5、audio_cfg_scale=1.3)
- 動画を生成してMP4としてエクスポート
このような手順を踏むことで、数分〜十数分の作業で、1080p解像度の自然なリップシンク付きキャラクター動画が完成します。
まとめと今後の展望(再)
WanGPとMultitalkを活用すれば、音声さえ用意すれば自動で多人数会話動画を作れる時代が到来しています。GPU性能が控えめな環境でも、Vaceモデルや各種音声合成AIを組み合わせることで、表現の幅が広がります。今後はさらに軽量かつ高性能なモデルの登場や、UIの簡素化によって、初心者でもプロ品質の動画制作が可能になるでしょう。
この機会に、ぜひ自身のコンテンツ制作にWanGP+Multitalkを取り入れてみてはいかがでしょうか。
関連記事


